Problem Description
In array signal processing, a manifold of sensors is employed to produce observations of some measurable quantity. The type of signals measured by the array will depend on the application for which it is designed. For example sensor arrays have been used in such fields as communications, sonar, speech processing, manufacturing processes and image reconstruction.
- A common assumption is that we use narrowband signals for processing and that the system operates in the far-field. These assumptions are often done in multichannel radar processing, hence the name of this field of research.
- Impulsive noise has been considered as a more accurate description for the ambient noise in many communication channels, due to the impulsive nature of man-made electromagnetic interference and a large amount of natural interference. The presence of impulsive noise, which constitutes a deviation from the Gaussian assumption, causes performance degradation for classical methods.
- The focus of our work is to extract important information about the originating signals, which are observed at the array in the presence of impulsive noise. This information may be the number of sources, the spatial location of the sources or the originating source signals themselves.
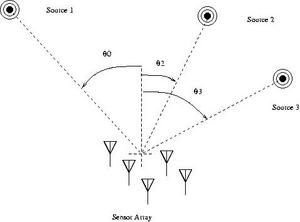
Source Number Estimation
Estimation of the number of sources impinging on an array of sensors is the critical first step in a subsequent signal parameter estimation in array signal processing. The most classical methods are based on inferring eigenvalue structure of the sample covariance matrix, with the help of information theoretic criteria (ITC) or hypothesis testing procedures. The presence of impulsive noise often causes large performance degradation of classical methods. The bootstrap-based multiple hypothesis testing relaxes the assumption of Gaussian data, which is, to some extent, more robust than other methods. However, its performance is very sensitive to impulsive noise which results in outliers in the observed data. This is because, as shown in some references, the bootstrap method has a very low breakdown point, since the simulated bootstrap distribution may be severely affected by bootstrap samples with a higher proportion of outliers than that in the original data set. Herein, we propose the use of robust statistics in order to prevent the expansion of outliers contamination in some bootstrap samples. Efficient integration of robust statistics into the bootstrap scheme is the most challenging issue in this research.
Direction-of-Arrival Estimation
Direction-of-arrivals (DOA) estimation is one of the most fundamental tasks in array processing in order to find the spatial location of the impinging sources. The classical methods for DOA estimation are based on the spatial covariance matrix of the observations. This work focuses on the DOA estimation of non-stationary sources such as FM signals. Interference signals in spread spectrum communications systems may belong to a class of FM signals. The latter are also encountered in the fields of radar and sonar. The energy contents of these sources are concentrated in well-defined regions in the time-frequency (TF) plane. Hence, time-frequency distributions (TFD) provide a natural mean for the analysis of non-stationary signals. These methods provide an improvement in the estimation accuracy and resolution capability by exploiting the TF signature of the signals present in the observations
Standard Spatial TFD estimators were derived under strict distributional assumptions, which, in practice, often are not valid and serious degradation of performance is experienced in nominally optimal methods. Consider, e.g., a situation where a DOA estimator of a nonstationary source, that has been designed based on distributional assumptions, performs best, i.e., is optimal in some sense, among other estimators developed under the same assumptions. Would that estimator still be best if the distribution would deviate from the assumed one? The answer is uncertain, unless the system has been designed under considerations of deviations from the assumptions made. Practical situations, such as in the example above, enforce the need for robust STFD estimators, which are close-to-optimal in nominal conditions and highly reliable for real-life data, even if the assumptions are only approximately valid.
To improve the reliability in face of impulsive noise, new estimators have been proposed in and have been applied to direction of arrival estimation of FM sources.
We have developed a generally applicable framework of robustness analysis of STFD matrix estimators. For this, we have applied the definition of the influence function and also its finite sample version, which is called sensitivity curve or empirical influence function, to STFD matrix estimators. We have analytically derived the influence functions of the standard and some recently proposed estimators which have been claimed to be robust. We have proven the robustness of the recently proposed estimators and have described differences between them for the asymptotic and the finite sample case. We have provided array processing examples for the influence functions and empirical influence functions in the case of a uniform linear array observing an FM source.
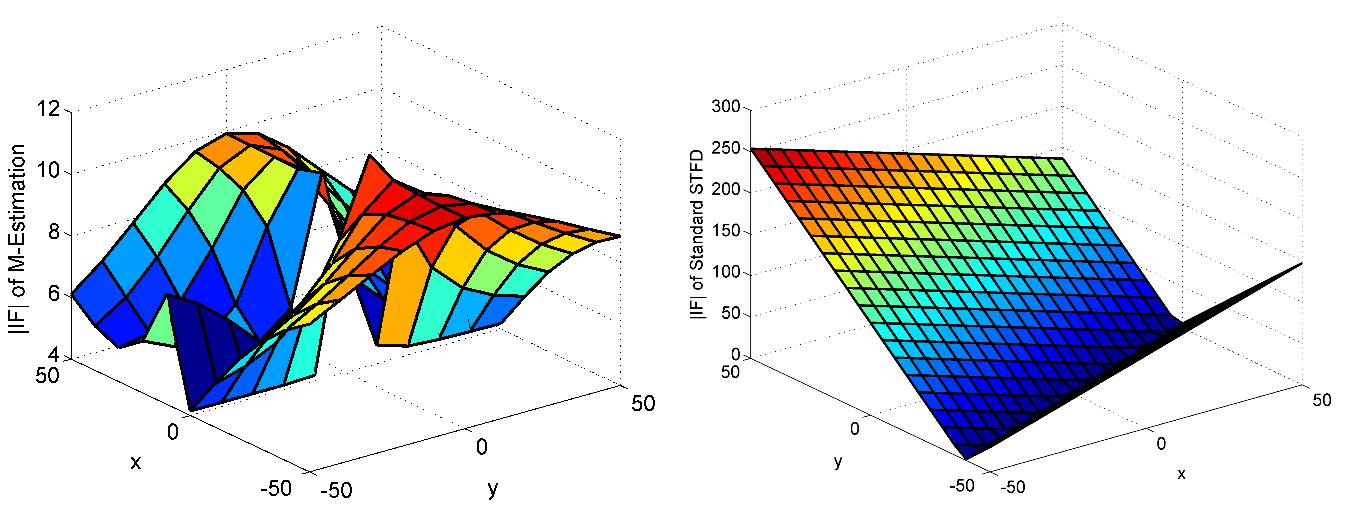
Boundedness of the influence function ensures that a small fraction of contamination, e.g., due to impulsive noise, can only have a limited effect on the bias of the estimate. Boundedness and continuity of the influence function together ensure qualitative robustness of the estimator.
Introductory Literature
- H. Krim and M. Viberg, “Two decades of array signal processing research: the parametric approach,” IEEE Signal Processing Magazine, Vol. 13 No. 4, July 1996.
- H.L. Van Trees, Optimum Array Processing, vol. 4 of Detection, Estimation and Modulation Theory, John Wiley & Sons, New York, 2002.
- M.G. Amin, Y. Zhang, “Direction finding based on spatial time-frequency distribution matrices,” Digital Signal Processing, vol. 10, no. 4, pages 325-339, October 2000.
- M. Wax and T. Kailath, “Detection of signals by information theoretic criteria,” IEEE Trans. Acoust., Speech, Signal Process., vol. 33, no. 2, pp. 387-392, April 1985.
Selected SPG Publications
- W. Sharif, M. Muma and A.M. Zoubir, “Robustness Analysis of Spatial Time-Frequency Distributions Based on the Influence Function”, IEEE Transactions on Signal Processing 61(8):1958-1971, April 2013
- W. Sharif, Y. Chakhchoukh and A.M. Zoubir ,“Robust Spatial Time-Frequency Distribution Matrix Estimation with Application to Direction-of-Arrival Estimation”, Signal Processing 91(11):2630-2638, November 2011
- W. Sharif, Y. Chakhchoukh and A. M. Zoubir ,“Direction-of-arrival estimation of FM sources based on robust spatial time-frequency distribution matrices” , IEEE Workshop on Statistical Signal Processing (SSP), Nice, France, June 2011
- Z. Lu, Y. Chakhchoukh and A. M. Zoubir ,“Source Number Estimation in Impulsive Noise Environments using Bootstrap Techniques and Robust Statistics” , IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP) Prague, Czech Republic, May 2011
- W. Sharif, P. Heidenreich and A. M. Zoubir ,“Robust Direction-of-Arrival Estimation for FM Sources in the Presence of Impulsive Noise” , Proc. of the 35th IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP) Dallas TX, USA March 2010.
- L. Cirillo, A. M. Zoubir, and M. Amin. “Direction finding of nonstationary signals using a time-frequency Hough transform”. In Proceedings of the 30th IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Philadelphia, USA, March 2005.
- R.F. Brcich, A.M. Zoubir and P. Pelin, “Detection of sources using bootstrap techniques,” IEEE Trans. Signal Process., vol. 50, no. 2, pp. .206-215, Feb. 2002.
Contact: For more information on this research project contact Prof. Abdelhak M. Zoubir.
